1 はじめに:晴れの日が続いても川が流れる謎
何週間も雨が降っていないのに、なぜ川の水は絶え間なく流れ続けているのだろうか?
山から水が流れ落ちてくるから、というのは部分的な答えに過ぎない。もし雨だけが川の源であるならば、雨が止んで数日もすれば、小さな川はすべて干上がってしまうはずである。
しかし、実際にはそうはならない。それは、目に見えない地表の下から、常に水が供給され続けているからである。この「雨が降っていない時期にも川に供給される、地下水由来の流れ」を基底流量(Baseflow)と呼ぶ。
川と地下水は独立した存在ではなく、砂や砂利の層を通じて密接につながっている。本記事では、川と地下水が交わす水のやり取りの仕組みと、その物理的・数理的背景、そしてPythonを用いたハイドログラフからの基底流量の分離手法について解説する。
2 川と地下水をつなぐ物理:得水河川と失水河川
河川と帯水層(地下水を蓄える地層)のつながり方は、地下水位と河川水位の相対的な高さ関係によって大きく二つに分類される (Freeze と Cherry 1979年)。

また、これらを上空から見下ろした「平面図」で表すと、以下のようになります。
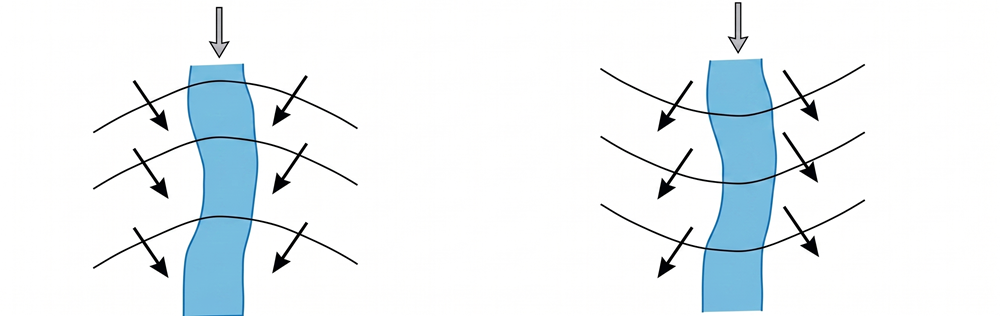
平面図(図 2)において、黒い曲線は地下水位の高さが等しい点を結んだ等水頭線(コンター)を、矢印は地下水が流れる方向(流線)を表しています。地下水は常に「高いところから低いところへ」と、等高線に直交するように流れます。得水河川(左)では等水頭線がV字型を描き矢印が川に集まる一方、失水河川(右)では逆V字型となり矢印が川から外へ広がることが分かります。
2.1 得水河川(Gaining Stream)
周りの地下水位が、川の水位よりも高い場合である(図 1 左)。 このとき、地下水は水頭勾配(水圧の差)に従って帯水層から川へと湧き出る。結果として、下流に行くほど川の流量は増加する。日本の湿潤な気候における多くの河川は、年間を通じてこの「得水河川」の状態にあり、これが雨が降らなくても川が涸れない最大の理由である。
2.2 失水河川(Losing Stream)
周りの地下水位が、川の水位よりも低い場合である(図 1 右)。 この場合、川の水は重力と水頭勾配によって川底から帯水層へと染み出していく。乾燥地域や、過剰な地下水揚水によって周囲の地下水位が低下した地域でよく見られる。このような川は、下流に行くほど流量が減少するか、あるいは完全に途中で干上がってしまう。
3 Pythonハンズオン:ハイドログラフの基底流量分離
実際の河川で観測される流量データ(ハイドログラフ)は、降雨の直後に急激に立ち上がる「直接流出(Quickflow)」と、地下水がじわじわと染み出す「基底流量(Baseflow)」が合わさったものである。
これら二つの成分を分離することは、流域の地下水涵養量を推定したり、渇水期の水資源量を予測したりするうえで極めて重要である。今回は、水文学で広く用いられる Lyne-Hollickのデジタルフィルタ法 をPythonで実装し、合成ハイドログラフから基底流量を分離してみよう。
3.1 Lyne-Hollick フィルタのアルゴリズム
Lyne & Hollick (Lyne と Hollick 1979年) によって提案された手法は、信号処理のローパスフィルタに似たアプローチで直接流出(高周波成分)を除去し、基底流量(低周波成分)を抽出する。
\[ q_t = \alpha q_{t-1} + \frac{1+\alpha}{2} (Q_t - Q_{t-1}) \]
\[ b_t = Q_t - q_t \]
ここで:
- \(Q_t\): 時刻 \(t\) における総河川流量 (\(m^3/s\))
- \(q_t\): 時刻 \(t\) における直接流出量 (\(m^3/s\))
- \(b_t\): 時刻 \(t\) における基底流量 (\(m^3/s\))
- \(\alpha\): フィルタパラメータ。通常 0.90〜0.995 の範囲(値が大きいほど基底流量が滑らかになる。日流量データでは 0.925 程度が定番)
※ 計算上の制約条件として、\(q_t \ge 0\) かつ \(b_t \ge 0\)(すなわち \(q_t \le Q_t\))を常に維持する。また、1回のフィルタリングでは流出のピークに対して位相の遅れが生じるため、順方向(Forward)にフィルタをかけた後、時系列を逆方向(Backward)にして再度かけ、それらを平均する「双方向パス(Forward-Backward pass)」を行うのが標準的である (Chapman 1991年)。
3.2 実装コード
以下のコードは、降雨イベントを模したダミーの流量データを作成し、デジタルフィルタを適用して基底流量を分離・可視化するためのスクリプトである(本記事の図を生成したコードそのもの)。
import numpy as np
import matplotlib.pyplot as plt
# 1. 疑似ハイドログラフデータの作成
np.random.seed(42)
days = 90
t = np.arange(days)
# 地下水由来の緩やかな基底流量(真値のモデル)
baseflow_true = 15.0 * np.exp(-t / 120.0) + 5.0 * np.sin(2.0 * np.pi * t / 365.0) + 10.0
# 降雨に伴う突発的な直接流出
quickflow = np.zeros(days)
storm_days = [15, 45, 70]
storm_magnitudes = [45.0, 60.0, 35.0]
for sd, mag in zip(storm_days, storm_magnitudes):
for i in range(days):
if i >= sd:
quickflow[i] += mag * np.exp(-(i - sd) / 3.0) # 指数減衰流出
# 総流量 = 基底流量 + 直接流出 + 観測ノイズ
total_flow = baseflow_true + quickflow + np.random.normal(0, 0.5, days)
total_flow = np.clip(total_flow, 1.0, None)
# 2. Lyne-Hollick デジタルフィルタの適用 (双方向パス)
alpha = 0.925
# 順方向パス (Forward Pass)
q_f = np.zeros(days)
for i in range(1, days):
q_f[i] = alpha * q_f[i-1] + 0.5 * (1 + alpha) * (total_flow[i] - total_flow[i-1])
# 制約条件の適用
if q_f[i] < 0:
q_f[i] = 0
elif q_f[i] > total_flow[i]:
q_f[i] = total_flow[i]
# 逆方向パス (Backward Pass)
q_b = np.zeros(days)
for i in range(days-2, -1, -1):
q_b[i] = alpha * q_b[i+1] + 0.5 * (1 + alpha) * (total_flow[i] - total_flow[i+1])
if q_b[i] < 0:
q_b[i] = 0
elif q_b[i] > total_flow[i]:
q_b[i] = total_flow[i]
# 直接流出の推定値を平均化し、基底流量を算出
q_est = 0.5 * (q_f + q_b)
q_est = np.clip(q_est, 0, total_flow)
baseflow_est = total_flow - q_est
# 3. 美麗なプロットの作成
fig, ax = plt.subplots(figsize=(10, 6))
fig.patch.set_facecolor('#F8F9FA')
ax.set_facecolor('#F8F9FA')
ax.plot(t, total_flow, color='#1A365D', linewidth=2, label="総河川流量 Q(t)", zorder=4)
ax.fill_between(t, 0, baseflow_est, color='#90E0EF', alpha=0.8, label="推定基底流量 (地下水流出)", zorder=3)
ax.fill_between(t, baseflow_est, total_flow, color='#F6AD55', alpha=0.5, label="推定直接流出 (降雨流出)", zorder=2)
ax.set_xlabel("経過日数 (Days)", fontsize=12, fontweight='bold', color='#2D3748')
ax.set_ylabel("流量 (m³/s)", fontsize=12, fontweight='bold', color='#2D3748')
ax.set_title("ハイドログラフの基底流量分離", fontsize=16, fontweight='bold', color='#1A365D', pad=15)
ax.set_xlim(0, days-1)
ax.set_ylim(0, 100)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_color('#CBD5E0')
ax.spines['bottom'].set_color('#CBD5E0')
ax.grid(axis='y', alpha=0.4, color='#E2E8F0', linestyle='--')
ax.legend(loc="upper right", frameon=True, facecolor='#F8F9FA', edgecolor='#CBD5E0')
plt.tight_layout()
plt.show()3.3 コードの初心者向け解説
上記のPythonスクリプトで何をしているのか、少しだけ紐解いてみましょう。
np.random.seed(42)とデータの作成 まずは実験用のダミーデータを作ります。baseflow_trueでは「ゆっくり変化する地下水」を、quickflowでは「雨が降って急激に増える水」を数式で表現し、それらを足し合わせてtotal_flow(総流量)を作っています。q_f = np.zeros(days)とforループnp.zerosは「ゼロがずらっと並んだ箱(配列)」を用意する命令です。その後のfor i in range(...)というループを使って、1日目から順番に「昨日までの流量」と「今日の流量変化」を少しずつ足し合わせていきます。これがデジタルフィルタの正体です。np.clipによる安全装置 計算の途中で「川の流量よりも大きな地下水が湧き出す」といった物理的におかしな数字が出ないよう、np.clipという関数を使って「必ず0以上、総流量以下に収まるように」上限と下限を切り揃えています。- 双方向パス(Forward-Backward pass) 時間を過去から未来へ進める(順方向)だけでなく、未来から過去へ遡る(逆方向)計算も行い、両者の平均をとっています。これにより、計算結果のグラフが「右にズレる(位相が遅れる)」のを防ぎ、雨が降った瞬間に正しくピークが来るようになります。
3.4 フィルタ結果の考察
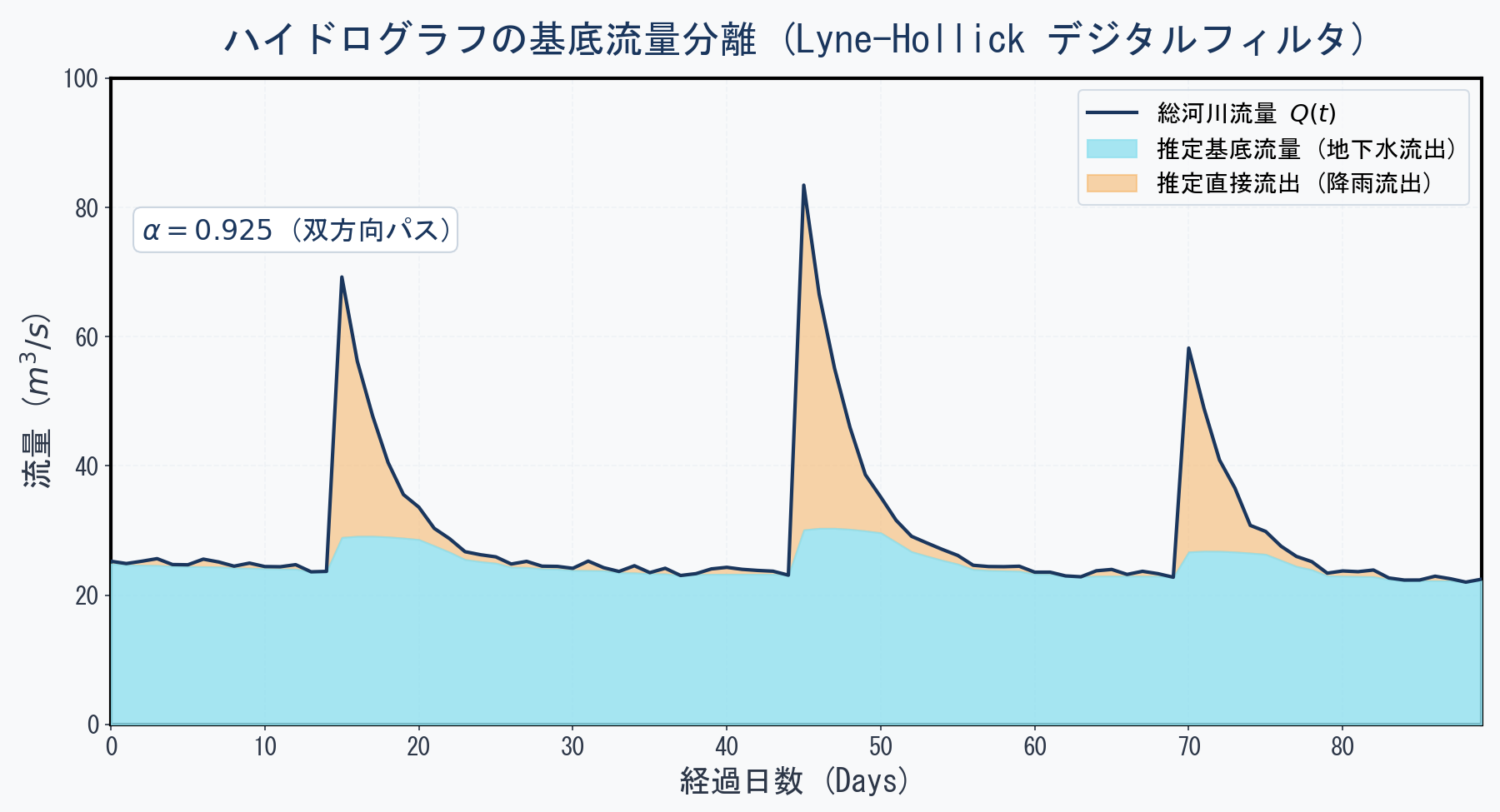
分離結果(図 3)を見ると、雨が降って河川流量が急増したピーク期(オレンジ色の領域)においても、地下水からの供給分である基底流量(水色の領域)は急激には上昇せず、遅れて緩やかにピークを迎え、その後も長い時間をかけてゆっくりと減少(減衰)していく様子が綺麗に表現されている。
このなだらかな曲線こそが、多孔質な地盤という巨大なフィルターを通過して川にたどり着いた「地下水の時間スケール」を体現している。
4 まとめ:流域水循環における河川と地下水の一体管理
今回のポイントを整理しよう。
- 基底流量(Baseflow)は雨が降らない時期に川を流れる水の源であり、その大部分は地下水である。
- 川と地下水の関係は、水位差によって得水河川(周囲から川へ湧出)と失水河川(川から周囲へ浸透)に分かれる。
- Pythonを用いたLyne-Hollickのデジタルフィルタ法により、観測流量から基底流量を視覚的に分離・定量評価できる。
川の汚染や水不足を解決するためには、川の水だけを見ていては不十分である。川に流れ込む地下水、あるいは川から染み出す地下水という「地表下の水循環」を一体(Conjunctive Use / Conjunctive Management)として捉え、管理することが持続可能な水資源利用には不可欠である。
5 次回予告
次回は「時系列解析&FFT」がテーマとなる。
別府南部の不圧地下水位の長期低下データを出発点に、信号処理(高速フーリエ変換: FFT)や統計解析を用いて、肉眼では見えない地下水の変動周期や大気圧・潮汐に対する応答を分離・定量化する手法について解説する。